说明
通过eBPF可以对多种类型的事件进行跟踪,例如:kprobe,kretprobe,tracepoint,uprobe,uretprobe,socket filter,tc filter,perf events等等.
下面将举例说民如何针对每种事件进行跟踪.
kprobe
Linux kprobes调试技术是内核开发者们专门为了便于跟踪内核函数执行状态所设计的一种轻量级内核调试技术。利用kprobes技术,内核开发人员可以在内核的绝大多数指定函数中动态的插入探测点来收集所需的调试状态信息而基本不影响内核原有的执行流程。
kprobes技术目前常用的探测技术是kprobe和kretprobe。
kprobe 允许在内核函数的入口处插入一个断点。当 CPU 执行到这个位置时,会触发一个陷入(trap),CPU 切换到你预先定义的处理函数(probe handler)执行。这个处理函数可以访问和修改内核的状态,包括 CPU 寄存器、内核栈、全局变量等。执行完处理函数后,CPU 会返回到断点处,继续执行原来的内核代码。
kretprobe 允许在内核函数返回时插入探测点。这对于追踪函数的返回值或者函数的执行时间非常有用。kretprobe 的工作原理是在函数的返回地址前插入一个断点。当函数返回时,CPU 会先跳转到你的处理函数,然后再返回到原来的地址。
有关kretprobe和kprobe的使用可以具体参考Linux内核源代码,kprobe_example.c
当然,也不是所有的函数都是支持kprobe机制,可以通过cat /sys/kernel/debug/tracing/available_filter_functions查看当前系统支持的函数.
使用eBPF可以大大简化原先kprobe的使用方式。以kprobe为例,原先的使用方式如下:
1 | /* |
使用kprobe针对do_fork进行探测,首先kprobe是有其特定的开发模式,其次最后需要将kprobe代码编译成为一个LKM模块加载到内核中才能使用。除了开发比较繁复之外,还因为是通过LKM加载到内核中,还容易造成内核崩溃。
使用eBPF使用kprobe机制就很简单。如下所是:1
2
3
4
5
6SEC("kprobe/vfs_mkdir")
int kprobe_vfs_mkdir(void *ctx)
{
bpf_printk("mkdir (vfs hook point)\n");
return 0;
};
通过SEC("kprobe/vfs_mkdir")就表明了需要Hook的是krpobe机制中的vfs_mkdir函数。
基于eBPF的kprobe技术示例代码参考:kprobe
kretprobe
kretprobe的使用基本上和kprobe是一致的,只是需要将SEC("kprobe/vfs_mkdir")改为SEC("kretprobe/vfs_mkdir")即可。
凡是可以使用kprobe的地方,都可以使用kretprobe。
基于eBPF的kretprobe技术示例代码参考:kretprobe
运行之后最终得结果输出是:1
2
3
4cat /sys/kernel/debug/tracing/trace_pipe
<...>-174894 [010] d...1 3306563.349353: bpf_trace_printk: kprobe,mkdir (vfs hook point)
___go_build_kpr-174894 [010] d...1 3306563.349403: bpf_trace_printk: kretprobe,mkdir (vfs hook point)
当然出了直接是用SEC("kprobe/vfs_mkdir")和SEC("kretprobe/vfs_mkdir")标明是kprobe和kretprobe之外,还是可以通过在bpf_tracing.h中的BPF_KPROBE和BPF_KRETPROBE的宏定义
来进行说明。
1 |
|
BPF_KRETPROBE 宏定义的 eBPF 程序是用于处理 kretprobe 事件的,这些事件在内核函数返回时触发。在函数返回时,其输入参数可能已经被改变或覆盖,因此 kretprobe 不提供输入参数。相反,它提供了函数的返回值,这是通过 PT_REGS_RC(ctx) 获取的,其中 ctx 是一个指向 struct pt_regs 的指针,PT_REGS_RC(ctx) 是一个宏,用于从 struct pt_regs 中提取函数的返回值。
在 BPF_KRETPROBE 宏定义中,首先声明了一个原型函数 name(struct pt_regs *ctx),然后定义了一个内联函数 ____##name(struct pt_regs *ctx, ##args),并在 name(struct pt_regs *ctx) 中调用了 ____##name(___bpf_kretprobe_args(args))。
___bpf_kretprobe_args(args) 是一个宏,它接受一系列参数,然后返回一个参数列表,这个列表的第一个元素是 ctx,后面的元素是函数的返回值 (void *)PT_REGS_RC(ctx)。这就是 BPF_KRETPROBE 提供的 “可选的返回值”。
然后,____##name(___bpf_kretprobe_args(args)) 会将这个参数列表传递给 ____##name 函数,这个函数就可以使用这些参数进行处理。在这个函数中,程序员可以使用 ctx 来访问 struct pt_regs,并使用 PT_REGS_RC(ctx) 来访问函数的返回值。
因此,从代码层面上来看,BPF_KRETPROBE 提供了一个可选的返回值(以及 struct pt_regs *ctx),而没有输入参数。
利用bpf_tracing.h中的BPF_KRETPROBE宏定义,可以将上面的kretprobe的示例代码改写为:
1 | SEC("kprobe/vfs_mkdir") |
利用这个BPF_KRETPROBE的好处就是通过PT_REGS_PARM1(ctx)得到相应的参数。
具体代码可以参考:kprobe_bpf
tracepoint
tracepoints 是 Linux 内核中的一种机制,它们是在内核源代码中预定义的钩子点,用于插入用于跟踪和调试的代码。tracepoints 在内核中的特定位置被硬编码,每个 tracepoint 都有一个唯一的名称和一组相关的参数。
tracepoints 的主要优点是它们对性能的影响非常小。当没有激活 tracepoint 时,它几乎不会影响系统性能。只有当一个 tracepoint 被激活,并且有一个或多个回调函数(也称为探针)附加到它时,它才会消耗 CPU 时间。这使得 tracepoints 非常适合在生产环境中使用,因为它们可以在需要时打开,而在不需要时关闭,以最小化性能影响。
tracepoints 的另一个优点是它们提供了一种稳定的 ABI(应用程序二进制接口)。这意味着,即使在内核版本升级后,tracepoint 的名称和参数不会改变,这使得开发者可以编写依赖于特定 tracepoint 的代码,而不用担心在未来的内核版本中这些 tracepoint 会改变。
在 eBPF 中,你可以使用 tracepoint 来捕获内核中发生的事件。你可以编写一个 eBPF 程序,然后将它附加到一个 tracepoint 上。当 tracepoint 被触发时,你的 eBPF 程序会被调用,你可以在你的 eBPF 程序中访问 tracepoint 的参数,以获取有关事件的详细信息。
tracepoints 和 kprobes/kretprobes 都是 Linux 内核中用于动态跟踪的机制,但它们在使用和性能方面有一些关键的区别。
以下是 tracepoints 和 kprobes/kretprobes 的一些优缺点:
tracepoints:
优点:
稳定性:
tracepoints是在内核源代码中预定义的,提供了稳定的 ABI。即使内核版本升级,tracepoint的名称和参数也不会改变,这使得开发者可以编写依赖于特定tracepoint的代码,而不用担心在未来的内核版本中这些tracepoint会改变。性能:
tracepoints对性能的影响非常小。只有当tracepoint被激活,并且有一个或多个回调函数(也称为探针)附加到它时,它才会消耗 CPU 时间。这使得tracepoints非常适合在生产环境中使用。
缺点:
- 可用性:
tracepoints的数量和覆盖范围有限。并非所有的内核函数都有对应的tracepoint,这限制了你可以监控的事件。
有关tracepoint的具体介绍可以看 tracepoint机制介绍 这篇文章.
socket
socket就是和网络包相关的事件,常见的网络包处理函数有sock_filter和sockops。eBPF所有可以处理的事件类型都在bpf.h文件中定义。
其中和socket相关的事件有:
BPF_PROG_TYPE_SOCKET_FILTER: 这种类型的 eBPF 程序设计用于处理网络数据包BPF_PROG_TYPE_SOCK_OPS和BPF_PROG_TYPE_SK_SKB: 这两种类型的 eBPF 程序设计用于处理 socket 操作和 socket 缓冲区中的数据包BPF_PROG_TYPE_SK_MSG:用于处理 socket 消息
BPF_PROG_TYPE_SOCKET_FILTER 对应的eBPF代码是:
1 |
|
这段 eBPF 代码是一个 socket filter 程序,它不需要绑定到特定的内核函数上。相反,socket filter 程序会被附加到用户态创建的套接字上,然后对通过该套接字收发的所有数据包进行处理。
SEC("socket/sock_filter") 是一个标记,表示这个 eBPF 程序应该作为一个 socket filter 使用。当你在用户态加载这个程序并将其附加到一个套接字上时,每当有新的数据包经过这个套接字时,这个程序就会被执行。
在这个程序中,bpf_printk("new packet received\n"); 语句会在每次接收到新数据包时向内核日志输出一条消息。返回值 0 表示该数据包应被接受(即,不被丢弃)。
所以,对于这种类型的 eBPF 程序,你不需要指定要绑定的内核函数。你只需要在用户态创建一个套接字,并将这个 eBPF 程序附加到这个套接字上。
对应用户端的代码如下:
1 |
|
通过m.Probes[0].SocketFD = sockPair[0],将创建的socket/sock_filter对应的程序绑定到sockPair[0](即,socket的输入上).
1 | func trigger(sockPair SocketPair) error { |
通过syscall.Write(sockPair[1], nil)和syscall.Read(sockPair[0], nil)触发eBPF的执行.
实际的运行结果如下:1
2sudo cat /sys/kernel/debug/tracing/trace_pipe
___go_build_soc-3814323 [009] d...1 1508306.501709: bpf_trace_printk: new packet received
成功输出new packet received,说明程序成功执行.
sockops
除了有BPF_PROG_TYPE_SOCKET_FILTER,还有BPF_PROG_TYPE_SOCK_OPS类型的事件,BPF_PROG_TYPE_SOCK_OPS 类型的 eBPF 程序用于 TCP 事件的处理,例如连接的建立和断开、拥塞控制等。这种类型的程序可以用于获取和修改 socket 操作的各种参数,例如发送和接收窗口的大小,重传超时时间等。
代码可以参考:bpf_sockops.c
当然也可以参考本项目写的代码:sockops
内核态的代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
SEC("sockops")
int bpf_sockops(struct bpf_sock_ops *skops)
{
switch (skops->op) {
default:
bpf_printk("eBPF sockops : %d \n",skops->op);
}
return 0;
}
char _license[] SEC("license") = "GPL";
__u32 _version SEC("version") = 0xFFFFFFFE;
bpf_sock_ops在文件bpf.h中定义。由于bpf_sock_ops的定义较长,这里只列出部分代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21struct bpf_sock_ops
{
__u32 op;
union {
__u32 args[4]; /* Optionally passed to bpf program */
__u32 reply; /* Returned by bpf program */
__u32 replylong[4]; /* Optionally returned by bpf prog */
};
__u32 family;
__u32 remote_ip4; /* Stored in network byte order */
__u32 local_ip4; /* Stored in network byte order */
__u32 remote_ip6[4]; /* Stored in network byte order */
__u32 local_ip6[4]; /* Stored in network byte order */
__u32 remote_port; /* Stored in network byte order */
__u32 local_port; /* stored in host byte order */
__u32 is_fullsock; /* Some TCP fields are only valid if
* there is a full socket. If not, the
* fields read as zero.
*/
.....
};
内核态的代码含义很简单明确。根据 skops->op 的值进行分支处理。struct bpf_sock_ops 是一个用于描述 socket 操作的结构体,其中的 op 字段表示当前的操作类型。默认情况下会通过bpf_printk输出。
用户态代码:
1 | func trigger() { |
因为sockops是针对TCP事件的处理,所以可以通过构造一个网络事件来触发sockops的执行。
在使用 eBPF 进行网络监控和处理时,指定 sockops 的 CGroupPath 是为了将 eBPF 程序限定在特定的 cgroup2 控制组中生效。
cgroup(控制组)是 Linux 内核中的一个特性,用于对进程进行分组和限制资源的使用。通过将 eBPF 程序关联到特定的 cgroup2 控制组,可以实现对该组内的进程进行网络流量监控和处理。
具体来说,sockops 在 eBPF 中是一个用于监控和处理套接字操作的功能或钩子。它允许你捕获和处理诸如套接字创建、连接、关闭等事件。通过指定 CGroupPath,你可以使 sockops 程序仅在特定的 cgroup2 控制组中生效,只监控该组内的套接字操作。
这样做的好处是可以针对特定的进程或应用程序进行网络监控和处理,而不会干扰其他进程或应用程序。同时,也能够提供更精细的网络流量控制和安全策略,增强系统的安全性和性能。
需要注意的是,指定 CGroupPath 前提是系统中已经挂载了 cgroup2 文件系统,并且相关的权限和配置已正确设置。否则,可能会导致无法在指定的 cgroup2 控制组中启用 eBPF 程序。
最终通过http.Get("https://www.bing.com/") 触发socket的执行,最终运行的结果如下所示:
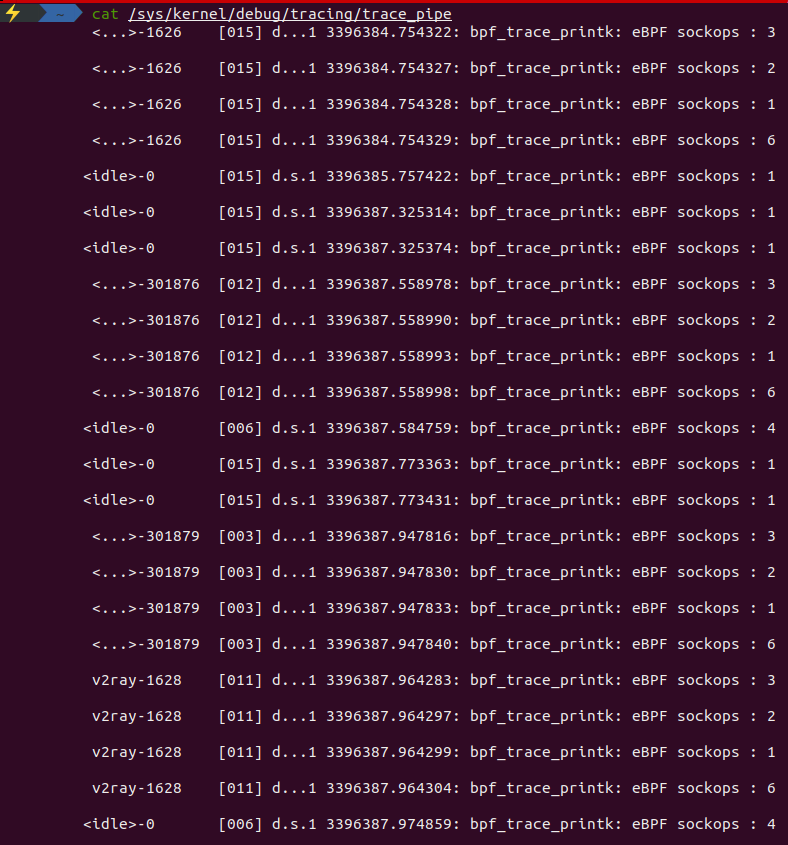
关于socket的妙用,可以参考 Cilium 基于 eBPF 实现 socket 加速 使用 eBPF 技术实现更快的网络数据包传输
tc
tc的全程是traffic control,即流量控制.通过tc可以对网络流量进行控制,例如限速,限流,负载均衡等等.从Kernel 4.1开始,TC支持加载eBPF程序到子系统的Hook点,并且在之后的Kernel 4.4中引入了direct-action模式,Cilium、Calico等网络插件大量使用TC Hook来控制网络包的转发。
子系统包括qdisc、class、classifier(filter)、action等概念,eBPF程序可以作为classifier被挂载。
想比较其他类型的事件,需要额外引入uapi/linux/pkt_cls.h文件. pkt_cls.h 头文件提供了一组用于数据包分类的常量、数据结构和函数原型,例如 struct __sk_buff 结构体,它是 eBPF 中用于表示网络数据包的重要数据结构。
内核态代码:1
2
3
4
5
6
7
8
9
10
11
12
13SEC("classifier/egress")
int egress_cls_func(struct __sk_buff *skb)
{
bpf_printk("new packet captured on egress (TC)\n");
return TC_ACT_OK;
};
SEC("classifier/ingress")
int ingress_cls_func(struct __sk_buff *skb)
{
bpf_printk("new packet captured on ingress (TC)\n");
return TC_ACT_OK;
};
其中egress表示的出流量,ingress表示的是进流量,TC_ACT_OK表示数据包在经过 TC 分类器处理后,应该继续传递到下一个阶段或进行转发操作。
用户态代码:
1 | m := &manager.Manager{ |
相比之前事件类型,tc的Probe配置也额外多了几项,分别是Ifname,SkipLoopback,NetworkDirection
Ifname:指定要附加到的网络接口的名称。这是一个字符串,需要根据实际运行的机器上的网卡地址的名称进行修改,常见的网卡名称就是"eth0"。在本机上,可以通过ip addr命令查看网卡名称。SkipLoopback:指示是否跳过回环设备的标志。当设置为true时,如果数据包是通过回环设备(loopback)发送或接收的,则不会触发 eBPF 程序。这在一些情况下很有用,因为回环设备上的数据包通常不需要进行额外的处理。NetworkDirection:指定网络流量的方向。它可以是manager.Ingress(入站)或manager.Egress(出站)。这决定了 eBPF 程序将被应用于哪个方向的流量。请注意,在某些情况下,如果你在虚拟以太网对的主机侧进行挂钩,则 Ingress 和 Egress 的含义可能会相反。
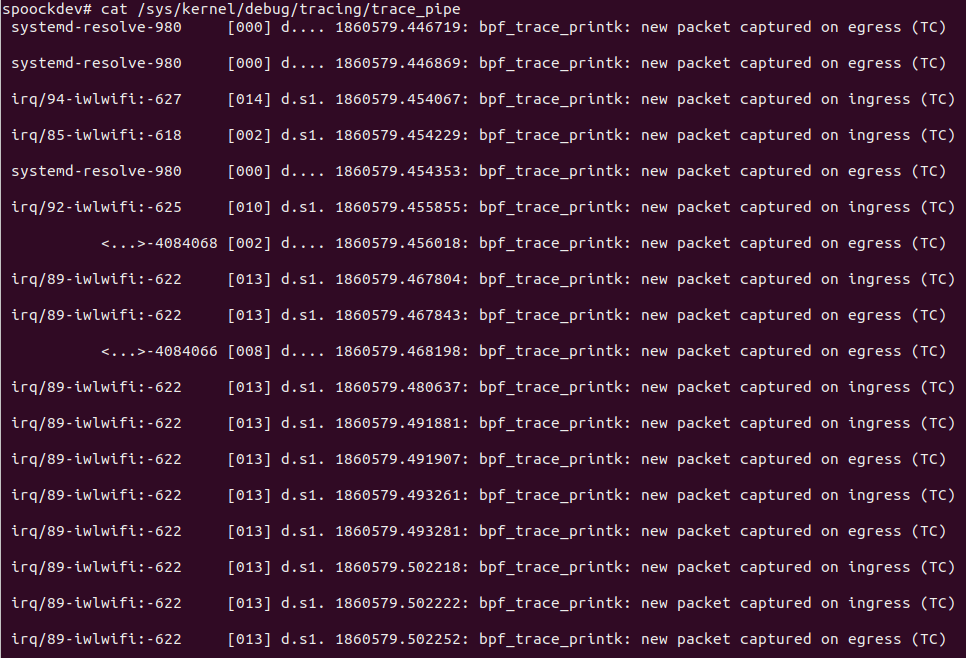
xdp
XDP机制的主要目标是在接收数据包时尽早处理它们,以提高网络性能和降低延迟。它通过将eBPF程序附加到网络设备的接收路径上来实现这一目标。具体而言,XDP程序会在数据包进入网络设备的接收队列之前执行,这样可以在内核中进行快速的数据包过滤和处理,而无需将数据包传递给用户空间。
tc(Traffic Control)和xdp(eXpress Data Path)是Linux网络中两种不同的数据包处理机制,他们的区别如下:
位置不同:
tc位于Linux网络协议栈的较高层,主要用于在网络设备的出入口处对数据包进行分类、调度和限速等操作。而xdp位于网络设备驱动程序的接收路径上,用于快速处理数据包并决定是否将其传递给协议栈。执行时机不同:
tc在数据包进入或离开网络设备时执行,通常在内核空间中进行。而xdp在数据包进入网络设备驱动程序的接收路径时执行,可以在内核空间中或用户空间中执行。处理能力不同:
tc提供了更复杂的流量控制和分类策略,可以实现各种QoS(Quality of Service)功能。它可以对数据包进行过滤、限速、排队等操作。而xdp主要用于快速的数据包过滤和处理,以降低延迟和提高性能。
xdp和tc的代码基本相同,除了Section不同之外,其他的都是一样的.
1 | SEC("xdp/ingress") |
用户态的代码也和tc的代码一致,也不做说明了.
uprobe
uprobe是”User Probe”的缩写,它利用了Linux内核中的ftrace(function trace)框架来实现。通过uprobe,可以在用户空间程序的指定函数入口或出口处插入探测点,当该函数被调用或返回时,可以触发事先定义的处理逻辑。kprobe是用于监控内核态的程序,uprobe就是用于监控用户态的程序.
目前uprobe最常用的做法就是用在获取bash的命令.
内核态代码:1
2
3
4
5
6SEC("uprobe/readline")
int uprobe_readline(void *ctx)
{
bpf_printk("new bash command detected\n");
return 0;
};
这个内核态的代码是用于监控bash的命令的,当bash的命令被执行时,就会触发uprobe_readline的执行.基本上和其他类型的监控事件没有差别。
用户态代码:1
2
3
4
5
6
7
8
9
10m := &manager.Manager{
Probes: []*manager.Probe{
{
Section: "uprobe/readline",
EbpfFuncName: "uprobe_readline",
AttachToFuncName: "readline",
BinaryPath: "/usr/bin/bash",
},
},
}
uprobe监控相比其他类型事件的监控存在一个很明显的差别,需要额外配置BinaryPath。原因是因为uprobe针对用户态程序的监控,所以需要指定用户态程序的路径.在本例中,我们针对的是bash进程,所以需要指定/usr/bin/bash。
最终运行的结果如下所示:

总结
基本上将常见的eBPF支持的类型的原理和示例程序基本山编写完毕了。当然本文章只是简单地展示了eBPF的使用。有关eBPF更深入的使用以及更多的实际案例,后面会陆续更新。