说明
网络上大多数是借助bcc编写和学习eBPF编程,由于bcc封装了很多的实现细节,并不一定能够很好地方便了解eBPF的原理,本文借助ebpfmanager和golang来编写eBPF程序.
本篇文章先不讲eBPF背后高深的机制,只是简单地介绍eBPF的基本使用方法,后续会陆续更新eBPF的原理和更多的应用场景,方面对eBPF有一个清晰的认识.
运行机制
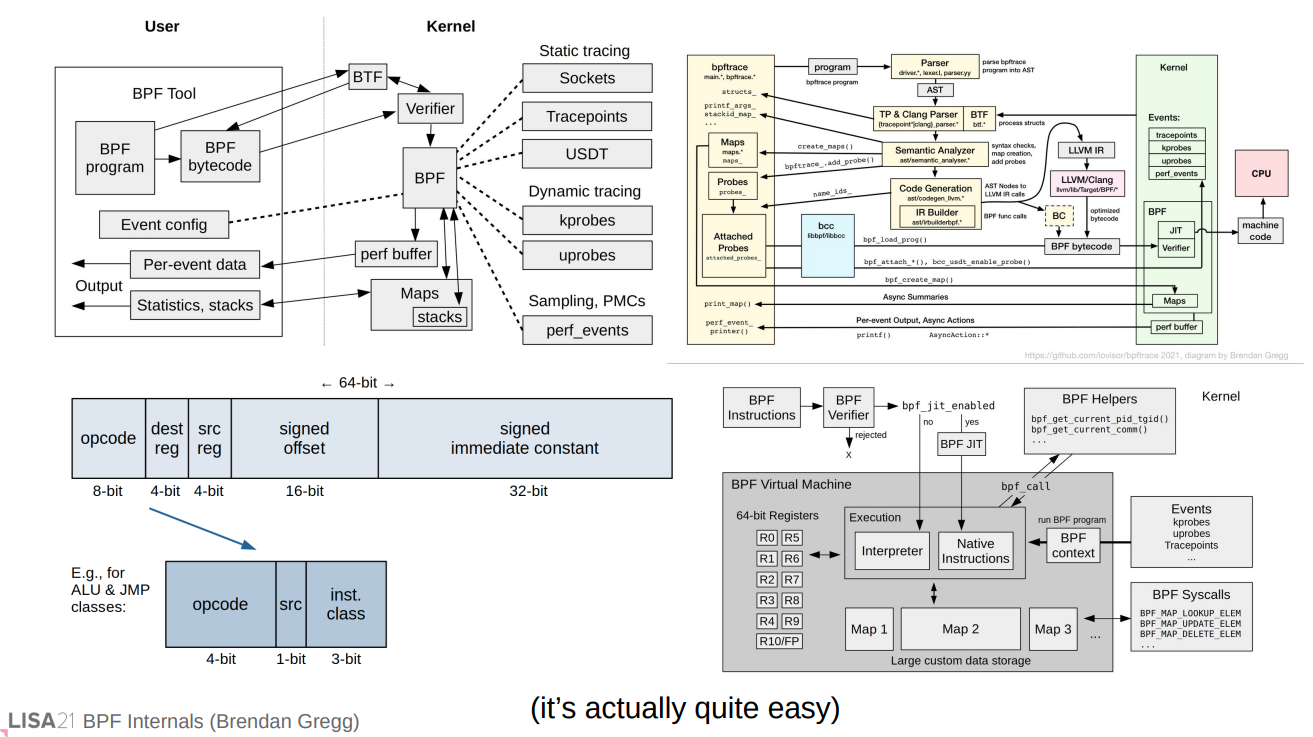
有关eBPF的运行机制,可以配合上面这张图来理解。
在用户端,编写eBPF程序代码,使用LLVM或者GCC编译得到eBPF字节码,然后通过bpf系统调用提交给内核执行,用户态通过 perf 事件(perf events)和 perf 缓冲区(perf buffers)来获得内核eBPF传输的数据。
在eBPF的内核态,首先会通过verifier来验证eBPF字节码的安全性,然后通过JIT编译器将eBPF字节码转换成BPF机器码,最后通过BPF虚拟机来执行BPF机器码。
程序框架
为了方便说明,编写了一个简单的程序框架,程序框架主要是参考了ebpfmanager中的示例代码.
为了保证程序能够成功运行,最好是在内核版本5.2+以上运行.
完整的代码可以参考:helloworld
内核态
1 |
|
首先分析SEC("kprobe/vfs_mkdir")代码的含义.
在 eBPF (扩展版伯克利分组过滤器) 编程中,SEC 是一个宏,用于给注入到内核的 BPF 程序定义一个段(section)。这个段的名称通常用于指明这个 BPF 程序应该怎样绑定到内核。
具体来说,SEC("kprobe/vfs_mkdir") 定义了一个叫 “kprobe/vfs_mkdir” 的段。这个段的名称指出,这个 BPF 程序将作为一个 kprobe(内核探针),并且应当在 vfs_mkdir 这个内核函数被调用的时候执行。在这个例子中,vfs_mkdir 是在文件系统进行创建目录操作时所调用的一个函数。所以,这段 BPF 程序实际上是在每当有新的目录被创建时执行。
当这个 BPF 程序加载进内核时,BPF 加载器会解析这个段名,并且创建一个绑定到 vfs_mkdir 的 kprobe。然后每当 vfs_mkdir 被调用时,这个 BPF 程序就会被触发。
这种通过 SEC 宏定段名的做法是 libbpf(一种常用的 BPF 加载库)的特性,它大大简化了 BPF 程序的加载和管理过程,使得 BPF 程序的编写者可以用更高级别、更直观的方式来描述他们希望的加载行为。
int kprobe_vfs_mkdir(void *ctx)在eBPF(扩展伯克利报文过滤器)的上下文中,这是一个用于响应内核事件(在这种情况下是vfs_mkdir函数调用)的处理函数
int:这是这个函数的返回类型。这个函数返回一个整数值,通常用于表述函数的执行情况。在eBPF程序中,0通常表示成功,而非零值表示发生了错误或其他特殊情况。kprobe_vfs_mkdir:这是我们正在定义的函数的名称。它通常与其对应的SEC("kprobe/vfs_mkdir")声明相匹配,以表示这是绑定到vfs_mkdir内核调用的处理程序。(void *ctx):这是函数的单个参数。“ctx”是一个指针,指向的是这个函数在被调用时(在这种情况下是响应vfs_mkdir执行)的上下文。这个上下文一般都是一系列寄存器.
总之,int kprobe_vfs_mkdir(void *ctx)这行代码是定义一个名为kprobe_vfs_mkdir的eBPF处理程序,当内核调用vfs_mkdir时,这个处理程序将被执行。
bpf_printk("mkdir (vfs hook point)\n");`: 这行代码使用 BPF 辅助函数 “bpf_printk” 在内核日志中输出一条消息 "mkdir (vfs hook point)\n",可以通过trace_pipe查看到具体的信息.
1 | cat /sys/kernel/debug/tracing/trace_pipe |
最后return 0;`:表示该 BPF 程序成功执行。
最后通过Makefile将这段代码编译得到bpf格式的文件,此时就可以加载进入到内核中.
通过如下的Makefile代码编译我们的ebpf代码,就可以获得ebpf字节码。
1 | build-ebpf: |
其中关键代码是llc -march=bpf -filetype=obj -o ebpf/bin/probe.o
llc 是 LLVM(Low Level Virtual Machine)的一部分,它是一个静态编译器,用于将 LLVM 中间表示(Intermediate Representation,IR)转换为目标机器代码。在这个上下文中,它被用于将 eBPF 程序从 LLVM IR 转换为 BPF 字节码。
-march=bpf:这个选项指定了目标架构为 BPF(Berkeley Packet Filter)。march 是 “machine architecture” 的缩写,指的是目标机器的架构。bpf 是一种在内核中运行的虚拟机架构,用于网络数据包过滤和事件跟踪。
-filetype=obj:这个选项指定了输出文件的类型为对象文件。对象文件是一种包含了机器代码但还没有被链接的文件,它可以被链接器(linker)链接到其他对象文件或库以生成可执行文件或库。
-o ebpf/bin/probe.o:这个选项指定了输出文件的路径。-o 是 “output” 的缩写。在这个例子中,输出文件将被保存在 ebpf/bin/probe.o。
用户态
在用户态,就需要借助ebpfmanager将编译好的bpf字节码文件加载到内核中. 有关ebpfmanager得具体使用可以参考,ebpfmanager
1 | m := &manager.Manager{ |
结合ebpfmanager的代码,具体到Probe的含义如下:
UID:这个字段可以用于在使用相同的 eBPF 程序在多个挂钩点时识别你的探针,是作为挂载点的唯一标识。Section:这个字段指的是程序的部分,如其在部分 SEC(“[section]”) 中定义的那样。需要注意的是,新版本的 ebpf 库 programSpec map 不再将字节码中的段信息作为索引,因此它不能用作 programSpec[] 的索引。索引改用 MatchFuncName。EbpfFuncName:这是要挂钩的系统调用的名称。由于确切的内核符号可能从一个内核版本到另一个内核版本有所不同,所以在运行时会自动计算正确的前缀。如果没有提供系统调用名称,那么假定部分名称(没有其探针类型前缀)是挂钩点。AttachToFuncName:这是用于查找要附加到的函数的模式。对于 KPROBES,当此选项被激活时,所提供的模式将与 /sys/kernel/debug/tracing/available_filter_functions 中的可用符号列表进行匹配。如果确切的函数不存在,那么将使用匹配所提供模式的第一个符号。这个选项需要 debugfs。对于 UPROBES,当此选项被激活时,所提供的模式将与提供的 elf 二进制文件的符号表中的符号列表进行匹配。如果确切的函数不存在,那么将使用匹配所提供模式的第一个符号。
m.Init(bytes.NewReader(_bytecode)),这行代码是将编译好的bpf字节码加载到内核中。
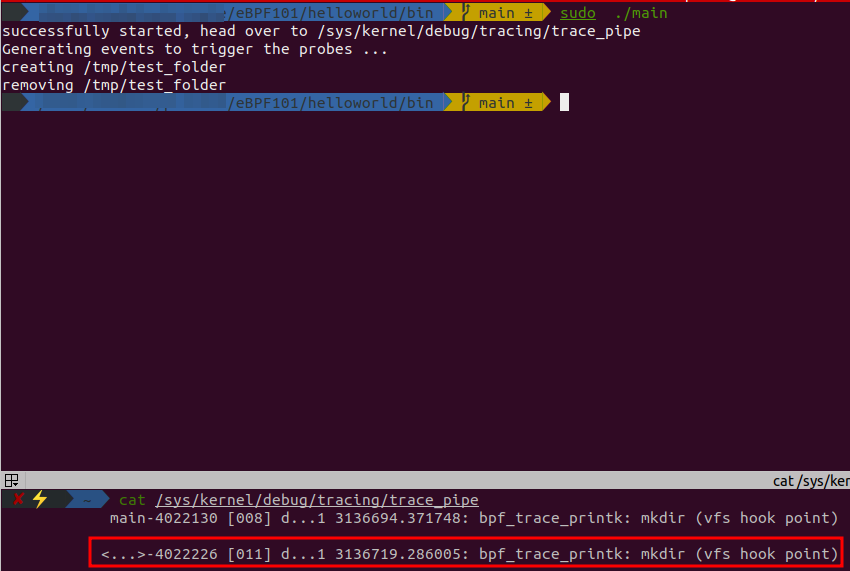
m.Start(),这行代码是启动ebpfmanager,此时就可以在trace_pipe中看到bpf程序的输出信息了.
通过trigger()创建目录和删除目录,触发vfs_mkdir的系统调用,从而触发了eBPF事件,最终就会执行bpf_printk("mkdir (vfs hook point)\n");,从而在trace_pipe中看到如下的输出信息.
总结
以上只是写了一个简单的eBPF程序示例,有关eBPF背后的原理和更多的应用场景,后续也会陆续更新系列博客.