说明
本文是一篇翻译稿,原文是:https://blog.kolide.com/osquery-under-the-hood-c1a8df46bb7a
在4年的时间里,有243个贡献者一共提交了4573个commit,为osquery的发展作出了贡献。osquery是一个复杂的项目,必须要兼备性能和稳定性,要要争能在数百万台的机器上面运行。本篇文章就是对osquery的整体架构进行一个简要的介绍。
本篇文章适用于那些对osquery的架构感兴趣,想为osquery发现贡献pr或者是想从成功的开源项目架构中学习的任何人。对于那些刚接触osquery来说,通过在macOS上面使用osquery也是一个很好的开始
架构说明
osquery的整体架构如下图所示:
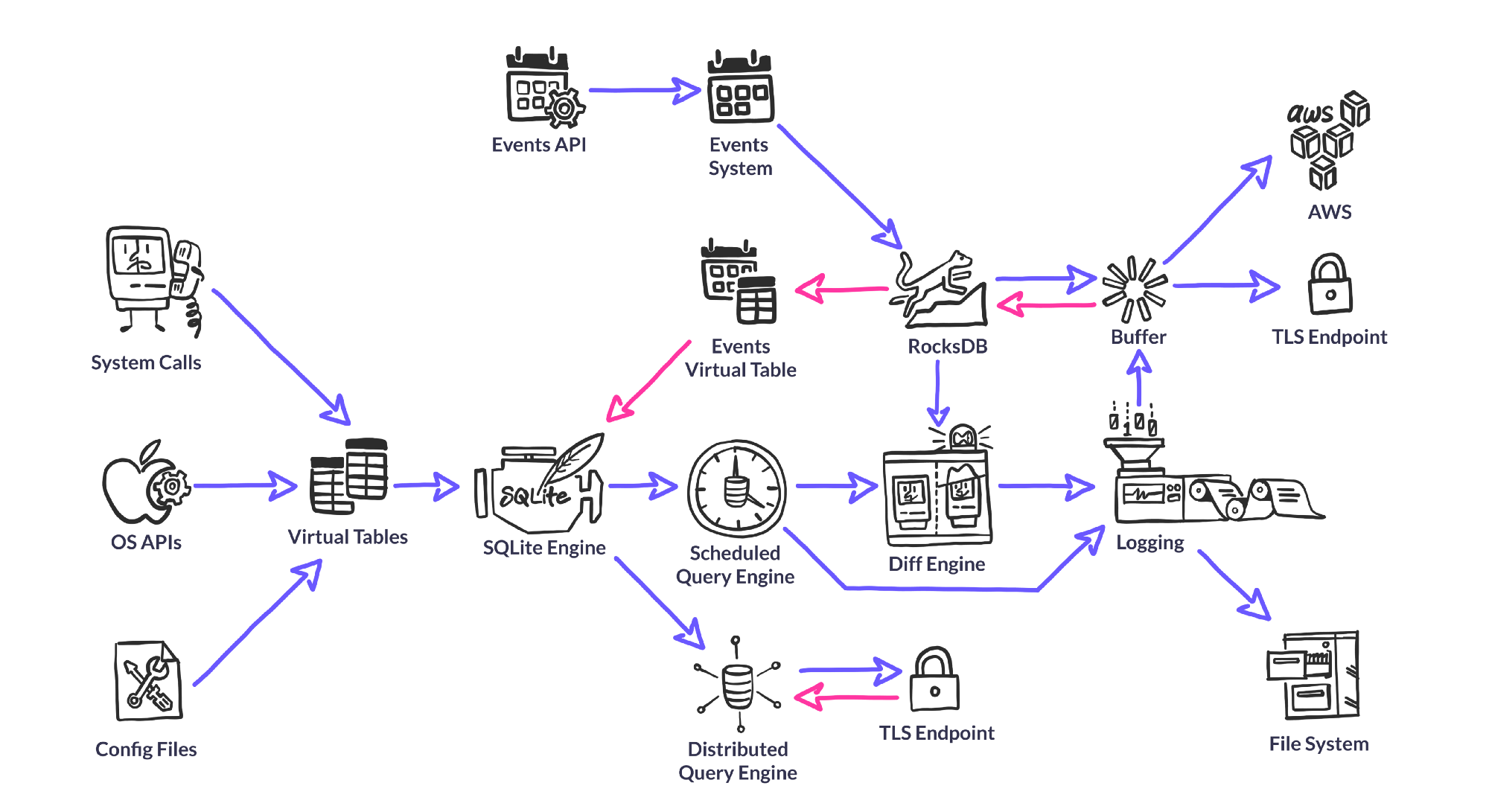
Query Engine
由于osquery良好的设计使得普通用户也能够使用SQL语句查询得到系统信息。osquery并没有完全使用sqlite,只是SQL的执行引擎是sqlite。osquery使用SQLite来解析、优化、执行SQL语句,使得osquery更加关注于解析系统信息。osquery底层并没有完全使用sqlite,仅仅只是查询引擎使用的是osquery
虽然osquery使用SQLite作为查询引擎,但是并没有使用SQLite来存储数据。大部分的数据都是在查询时通过一个虚拟表得到的。osquery通过嵌入的RocksDB来存储数据。
查询示例如下:
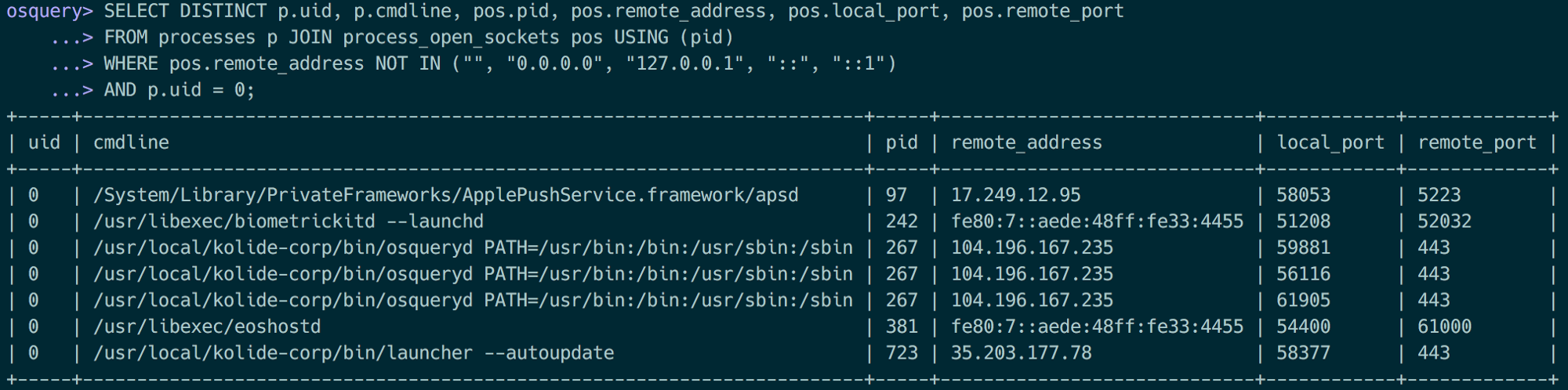
Virtual Tables
虚表是osquery的核心。虚表中保存了我们查询时的所有数据。当我们执行SQL查询时才会产生虚表数据。虚表数据一般都是通过解析文件或者是调用系统API来实现的
所有的表都是利用Python中的DSL来定义的。osquery通过读取这些文件来判断osquery有哪些表。在前面的文章中也已经说过,在osquery/specs/中就定义了osquery中所有的表。利用目录层次结构来判断他们支持哪些平台,例如osquery/specs/linux/表示支持的是Linux平台,osquery/specs/darwin/表示支持win平台。
在查询阶段,SQLite向虚拟表请求数据。osquery将SQLite的查询转换寻虚拟表能够确定是读取文件、调用系统API的方式生成数据。例如,对于虚拟表etc_hosts来说,虚拟表读取/etc/hosts文件然后解析每一行数据,甚至etc_hosts虚表不需要接受任何的外部约束,因为不管怎么样都会解析/etc/hosts整个文件。在虚拟表生成数据之后,通过SQLite中的Where语句进行过滤,然后在前段展示数据。但是像users这样的表就需要利用到查询上下文。虚拟表仅仅只会加载where条件中存在的uid或者是用户的相关数据,而不是检索所有的用户数据之后由SQLite来过滤显示,通过这样方式可以获得轻微地性能提升,在某些极端情况下性能提升更加明显。不同虚拟表的处理方式也不尽相同。对于hash表来说,比如通过通过where语句给出具体的文件,例如"select * from hash where path = '/etc/passwd'",。如果没有指定具体的文件名,那么osquery将会检索整个系统的文件,这将是一个灾难。所以如果查询hash表却没有指定任何的文件时,将会返回空。
鉴于osquery的良好的设计,使得普通人也能够很轻易地开发出一个虚拟表——创建一个简单的spec文件(使用Python内置的自定义DSL)然后使用C++实现。构建系统就会自动地编译,使得我们之后创建的表和之前的表都具有完全相同的作用和功能。如下方所示:
1 | table_name("etc_hosts", aliases=["hosts"]) |
Event System
并不是所有的osquery的数据都是在查询时产生。以文件完整性监控(FIM)为例来进行说明,假设这个FIM的定时任务是5分钟执行一次,那么如果攻击者在修改了文件内容之后又恢复了文件,那么定时任务无法发现这个行为。对于这种情况,我们需要一种能够持续性地监视变化情况。
为了解决这样的问题,osquery采用了一种publisher/subscriber模式。当虚拟表被查询时,这种模式能够产生、过滤、保存虚拟表的数据。Event publishers运行在他们自己的线程中,并且可以使用他们所需要的API来创建需要发布的事件流。对于Linux上面的FIM,publisher是利用inotify来产生事件。然后这个publisher会将这些消息发布给多个订阅者。这些订阅者就能够根据自己的需要,过滤或者是保存数据(数据是保存在RocksDB中)。最后,当用户查询一个基于事件的表是,相关的数据就能够被查询出来
Scheduler
在设计osquery的定时任务时,需要考虑很多的因素。考虑大规模地部署osquery,例如像osquery中部署了100万的主机,如果所有的主机在相同的时刻执行相同的查询语句而产生大量的数据,就会导致浪涌,这是一个非常严重的问题,所以这个定时任务提供了一个随机间隔,使得这些语句不会同时执行而是存在一点微小的时间间隔。这种微小的设计就能够避免浪涌。
还有一点需要注意的是,osquery的定时任务执行时间并不是以系统的时钟周期为准的,而是以osquery进程的时间为准的。例如在一个服务器上(假设服务器是24小时运行),那么osquery的定时任务的执行时间与系统的时钟是一致的。但是如果是一个笔记本(当用户盖上盖子时,系统就会休眠)处于休眠状态时,osquery也不会运行,那么此时定时任务也不会执行。
Diff Engine
由于每一次osquery的查询都会产生数据,为了避免产生大量的数据,osquery仅仅只是输出相较于上一次查询的差异。在每一次查询时,查询的结果都会保存在osuqery内部的rocksdb中。在输出查询结果时,osquery将当前的查询结果与上一次的查询结果进行比较,输出比较的结果(比较的结果包含了相较于上一次增加和删除的结果)。
osquery中还存在一种叫做snapshot模式(快照模式),在此模式下将不会进行比较,直接输出查询结果
RocksDB
虽然osquery的大部分数据都是在运行时刻才动态产生的,但是还是有部分数据需要保存,比如event类型的数据就需要保存。为了达到这个目的,osquery使用了rocksdb,rocksdb是快速存储和服务器工作负载的性能而设计。它应充分利用 Flash 或 RAM 提供的高速读/写速率。osquery使用rocksdb存储event类型的数据,柴艺华的数据以及一些配置信息,缓存数据等等。
想了解更多地有关rocksdb在osquery中的应用,可以看
Configuration Plugins
osquery可能会运行在各种系统中,那么此时就有可能从不同的地方地区配置信息。osquery采用了一个配置插件的方法来实现。配置插件将信息发送至osquery的守护进程。常见的配置源包括文件文件或者是TLS服务器。
配置插件的写法大致如下(GO语言示例):1
func LogString(ctx context.Context, typ logger.LogType, logText string) error
当扩展管理被调用时,配置插件就会返回一个JSON格式的配置信息,这个配置信息就会返回给osquery守护进程
Logger Plugins
和配置一样,日志也有可能需要发送至各种不同的收集端。常见的日志收集端包括文件系统(通常会使用splunkd或者是logstash转发),TLS,AWS Kinesis/Firehose
日志插件的写法日志如下(GO语言示例)1
func LogString(ctx context.Context, typ logger.LogType, logText string) error
当osquery产生日志时(status或者是result的日志)都会根据日志插件的配置发送至相应的地方
Distributed Plugins
分布式插件支持远程从osquery实时查询信息。目前分布式插件是采用TLS实现的。相较于Configuration Plugins和Logger Plugins是osquery中必须的部分,分布式插件却不是。分布式插件的最大优点就是能够实时查询(Kolide Fleet就是基于分布式插件实现的一款产品)
分布式插件的写法日志如下(GO语言示例)1
2func getQueries(ctx context.Context) (*distributed.GetQueriesResult, error)
func writeResults(ctx context.Context, results []distributed.Result) error
这些API运行osquery从远程获取查询语句并返回查询语句的执行结果
Static Compilation
为了保证osquery能够安装在各种不同的系统上,osquery能够编译成为一个单独的可执行文件(其中包含了它所需要的大部分依赖)。这个可执行文件包含了osqueryd和osqueryi以及osquery系统中内置的插件。
由于osquery是一个包含有大量依赖的C++项目,所以能够与快递编译出osquery是一个非常重要的问题。osquery的开发人员在这方面做了大量地工作,在编译过程中osquery会拉取/下载所需要的依赖然后编译为可执行程序。由于osquery将所需要的依赖都静态编译至程序中,所以osquery仅仅只需要一些基本的共享库,而这些库基本上在所有的系统上面都有,从而保证了osquery能够运行在多种不同的系统上面。
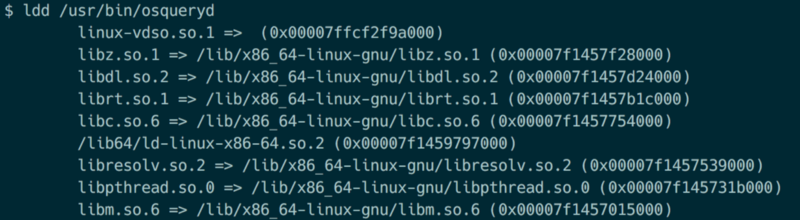
下图显示的就是osquery执行文件所需要的依赖
Watchdog
为了保证osquery对系统性能不会造成很大的影响,osquery有一个叫做watchdog的osquery进程,这个watchdog进程会创建一个子进程(work进程)用于监控所有的正在执行的查询,如果发现这个查询所占用的资源超过了预定义的阈值就会被kill掉。此外,watchdog还可以将频繁导致性能问题的查询语句加入黑名单,这样方便用户以后对这些查询语句进行优化。

其中pid为84的是watchdog进程,pid为267的是work进程
About the Author
Zach Wasserman长期为osquery提交代码并且是Kolide的首席工程师和创始人。下图显示的就是kolide的使用界面。
总结
本篇翻译大致将osquery的整体设计将清楚了,但是各个方面都是浅尝辄止,没有讲得很深入,如果需要详细了解osquery的过程设计就需要阅读osquery的源码了。