简介
在进行网站渗透的时候,如果能够知道网站使用的是什么PHP开源程序,那么就可以针对性进行利用攻击。所以对于知道了网站使用的开源程序,那么对之后的渗透将是非常有帮助的。最近实验室在研究Chrome插件安全机制方面的问题,我之前也写过一个简单的插件。之前看到有一个能够识别Web指纹的Chrome插件,正好可以用来回顾Chrome插件的原理同时也可以学习一下别人的思想。这款Chrome插件是websth,github地址。之前P牛有分析过,我也自己分析一遍吧。
websth
在分析websth之前,首先看一下这款插件的运行效果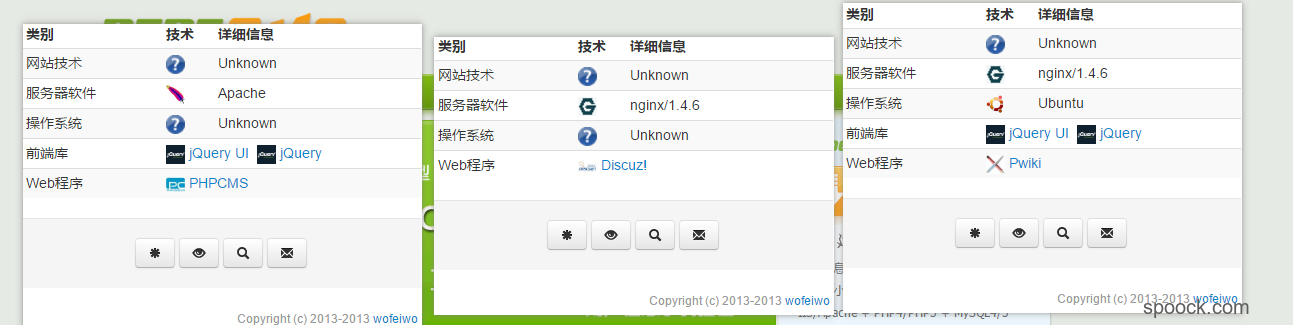
上面显示的分别是wensth识别phpcms、discuz、dedecms的结果,可以看到识别的效果并不是完全的正确。
manifest.json
Chrome插件的入口文件是manifest.json文件,通过这个文件基本上就可以知道有关这个插件所有的信息了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16"background": {
"scripts": [
"js/web_technologies.js",
"js/web_servers.js",
"js/oses.js",
"js/web_front_libraries.js",
"js/web_apps.js",
"js/background.js"
],
"persistent": true
},
"content_scripts": [ {
"js": ["js/website_analyzer.js"],
"matches": [ "http://*/*", "https://*/*" ],
"run_at": "document_end"
} ],
我们主要关注的是background和content_scripts。content_scripts中定义的js文件主要是与页面来进行交互的,background中定义的页面一般都是用来进行数据处理,可以同时与content_scripts中的js来进行交互,也可以和插件本身页面进行交互。
website_analyzer.js
首先看website_analysis.js的主函数1
2
3
4
5
6
7
8
9
10
11
12
13
14var client = new XMLHttpRequest();
client.open("HEAD", document.location.pathname, true);
client.send();
client.onreadystatechange = function() {
if (this.readyState == 2) {
var data = {
"header" : this.getAllResponseHeaders(),
"dom" : covertNodes(document),
"hostname" : hostname,
"port" : document.location.port
};
if (data) chrome.extension.sendMessage(data);
}
}
chrome.extension.sendMessage(data)就是将data数据传送到background中的js。有background中的js接受数据之后来进行识别。
其中的covertNodes的方法定义为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30function covertNodes(root){
var iterator = document.createNodeIterator(root, NodeFilter.SHOW_ALL, null, false);
var node = iterator.nextNode();
var nodes = [];
while(node){
if(node.nodeType == 1 || node.nodeType == 3 || node.nodeType == 8){ // element
// fix chrome bug
// chrome blows up here if value is an input that doesn't support
//one of these three properties ['selectionStart', 'selectionEnd', 'selectionDirection'] (e.g. <input type="file"/>)
if (node.nodeName == 'INPUT' || node.nodeName == 'TEXTAREA' || node.nodeName == 'FORM') {
node = iterator.nextNode();
continue;
}
nodes.push({
"nodeName" : node.nodeName,
"nodeValue": node.nodeValue,
"attributes": {
"src": node.src,
"href": node.href,
"name": node.name,
"content": node.content
},
"nodeType": node.nodeType
});
}
node = iterator.nextNode();
}
return nodes;
}
这个函数的定义用阿里遍历整个文档中所遇的节点,然后取出节点的信息,最后返回所有的节点的信息。
通过分析website_analyzer.js这个文件,我们总结一下这个文件的功能,就是提取文档中的信息,然后传递到background.js中。提取的信息包括所有的响应头、节点信息、主机名、以及端口号
background.js
background.js是在manifest中的background中定义的,这个就是插件集合了插件主要的功能。接下来就是分析代码了。1
2
3
4
5
6
7
8
9
10chrome.extension.onMessage.addListener(function(data, sender) {
technologyData[sender.tab.id] = parseHeader(data.header);
technologyData[sender.tab.id]['raw_header'] = data.header;
technologyData[sender.tab.id]['hostname'] = data.hostname;
technologyData[sender.tab.id]['port'] = data.port || 80;
technologyData[sender.tab.id]['title'] = sender.tab.title;
var root = data.dom;
var alt = "Unknown technology";
var ico = "unrecognized_technology.png";
var show_icon = localStorage["icon"];
这段代码就是接受website_analysis.js发送过来的data,将接受过来的所有数据保存在technologyData[sender.tab.id]中。其中sender.tab.id是Chrome插件的中的变量,知道data的数据来源是来自于那个Tab页。
通过调试,我们可以看到data中的信息。
IP信息
1 | if(data.hostname != null){ |
将hostname传递到ipinfodb网站上面进行查询,得到ip信息,保存到technologyData[sender.tab.id]['ip_info']中。
web_technologies
1 | var technology = matchRule(technologyData[sender.tab.id], web_technologies); |
分析web_technologies,利用matchRule(),传递的参数是technologyData[sender.tab.id]和web_technologies。web_technologies就是在文件web_technologies.js中定义的web_technologies数组。如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16var web_technologies = [
{
"icon": "ipyramid.ico",
"title": "iPyramid",
"match": "X-Powered-By",
"regex": "^iPyramid.*",
"url": "http://www.ipyramid.lt/"
},
{
"icon": "hostcms.ico",
"title": "Host CMS",
"match": "X-Powered-By",
"regex": "^HostCMS.*",
"url": "http://www.hostcms.ru/"
},
......
识别方式主要为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16function matchRule(data, rules) {
for (var i = 0; i < rules.length; i++) {
if (data[rules[i].match.toLowerCase()]) {
var result = data[rules[i].match.toLowerCase()].match(rules[i].regex);
// console.log(result);
if (result){
rules[i]['result'] = result;
return rules[i];
}
}
}
return {
title : "Unknown",
icon : "unrecognized_technology.png"
};
}
通过分析代码,我们知道,这个主要就是通过X-Powered-By的方式来匹配找到网站是什么技术。
webserver
webserver信息也是利用的是web_server.js中定义的web_servers数组来进行处理。
web_server.js的定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15var web_servers = [
{
"icon" : "4d_webstar_s.gif",
"title": "4D WebSTAR",
"match": "Server",
"regex": "^4D_WebSTAR_S.*"
},
{
"icon" : "aolserver.gif",
"title": "AOLserver",
"match": "Server",
"regex": "^AOLserver.*",
"url" : "http://www.aolserver.com"
},
.....
匹配方式就是利用Server来匹配regex
oses
操作系统的信息同样和上面的方式是一样的,这里不再进行分析了
前端技术
前端分析的分析代码与之前所讲的代码的方式不一样,具体为:1
2
3
4
5
6
7
8
9var front_libraries = []
for (var i in web_front_libraries) {
for (var j in web_front_libraries[i]['rules']) {
if (findNode(root, web_front_libraries[i]['rules'][j].type, web_front_libraries[i]['rules'][j].match, web_front_libraries[i]['rules'][j].name, web_front_libraries[i]['rules'][j].attributes)) {
front_libraries.push(web_front_libraries[i]);
break;
}
}
}
而其中的findNode()函数定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17function findNode(root, type, text, name, attr){
for (var node in root){
if(type == 1 && root[node].nodeType == type){ // element
if (root[node].nodeName.toUpperCase() == name.toUpperCase()){
var search_str = root[node].attributes[attr.toLowerCase()];
if (search_str.match(text)){
return true;
}
}
}else if(root[node].nodeType == type){ // text & comment
if (root[node].nodeValue.match(text)) {
return true;
}
}
}
return false;
}
这个利用的就是web_front_libraries.js,这个同样是定义了很多的匹配规则1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27web_front_libraries = [
{
"icon": "jquery.jpg",
"title": "jQuery UI",
"url" : "http://jqueryui.com",
"rules": [
{
"type": 1,
"name": "SCRIPT",
"attributes": "src",
"match": /jquery-ui.*/i
}
]
},
{
"icon": "bootstrap.jpg",
"title": "Bootstrap",
"url" : "http://twitter.github.com/bootstrap/",
"rules": [
{
"type": 1,
"name": "LINK",
"attributes": "href",
"match": /bootstrap.*/i
}
]
},
通过匹配规则和web_front_libraries就可以知道匹配的思路了。当节点的名称与规则中的名称相匹配的时候,就通过attributes来匹配match。如遇到如下的代码时:"name": "SCRIPT","attributes": "src","match": /jquery-ui.*/i,如果节点的名称是SCRIPT,就看节点的src属性是匹配为/jquery-ui.*/i,如果匹配,则说明是jquery-ui。
web app
web app的匹配原则利用的是web_app.js中的信息。方式和前端技术使用的是一样的方法。这里也不作过多的说明。
前端展示
通过background.js分析完毕之后,最后就是在页面上进行展示了,那么最后的步骤就是通过background.js将信息传递给popup.html了。
popup.html
在popup.html中引入了popup.js文件1
<script type="text/javascript" src="js/popup.js"></script>
popup.js
分析主要函数1
2window.addEventListener('load', main);
document.getElementById('show_header').addEventListener('click', showHeader);
当页面进行加载的时候,就会调用main函数。
看main函数的定义:1
2
3
4
5
6
7
8
9
10
11function main() {
chrome.tabs.getSelected(null, function(tab) {
var data = chrome.extension.getBackgroundPage().technologyData[tab.id];
// console.log(data);
if (data['ip_info']) {
......
}
if (data['technology']) {
......
}
.....
通过分析,发现var data = chrome.extension.getBackgroundPage().technologyData[tab.id];通过这种方式拿到background.js传递过来的页面,最后在popup.html上进行展示。这个就是利用JS进行HTML动态加载的常规代码,比较的简单。
至此,整个插件的代码就基本分析完毕了,还好不是特别的难,有点JS基础再加上对Chrome插件机制比较熟悉的话,就可以看懂这个代码了。
总结
通过分析,websth的识别web指纹的方法还是较为的简单,而且十分地不正确。识别方式主要是通过HTTP的响应头以及文档中的节点来进行判断的,但是这些信息很多时候都是不够的,这样就导致很多网站都无法分析出来。如果这个插件能够分析出来网站的指纹,那么我们只要通过打开Chrome Developer Tools一样是可以分析出来的。所以我个人认为websth的检测方法还是存在很大的问题。
我平时用的比较多的是御剑WEB指纹识别系统,御剑这款工具也是存储了很多的指纹信息,但是这些指纹信息一般都是一些特定的文件,通过请求这些文件,根据这些文件是否存在来确定WEB指纹。
相对而言,我认为御剑的方式更加靠谱,但是我目前也没有发现如何将御剑的这种方式应用在插件中,或者是通过插件有一个更好的方式来进行识别WEB指纹。